Nouvelle
Vialab est reconnu pour son expertise dans le domaine de la visualisation de l’information. Pouvez-vous nous en dire un peu plus sur ses activités de recherche et son expertise?
Vialab, ou Visualization for Information Analysis lab (laboratoire de visualisation pour l’analyse de l’information), est un groupe de recherche de l’Institut universitaire de technologie de l’Ontario, dirigé par Christopher Collins. Les travaux de recherche du laboratoire portent sur la visualisation de l’information, avec une attention particulière accordée à l’analyse des textes et des documents. Le laboratoire mène également des recherches sur l’interaction personne-machine, en mettant l’accent sur l’intégration de surfaces interactives, l’oculométrie et des dispositifs matériels novateurs avec applications analytiques. Les thèmes de recherche comprennent l’apprentissage assisté par ordinateur, les mots de passe et la sécurité, les sciences humaines numériques, l’analyse de la santé, l’extensibilité de la visualisation, la perception de la visualisation, la visualisation mobile et l’apprentissage machine explicable. Les travaux du Vialab ont fait l’objet de reportages dans des médias populaires tels que le New York Times Magazine, le Toronto Star et CBS Sunday Morning. Le laboratoire entretient des collaborations avec un éventail de chercheur.e.s universitaires au Canada et dans le monde, sans oublier ses collaborations industrielles avec des partenaires tels que Microsoft Research, VerticalScope et Quillsoft. Plus de 50 stagiaires de tous les niveaux d’études ont travaillé dans le laboratoire depuis 2011.
Dans le cadre du projet CO.SHS, Vialab développe une suite logicielle composée de cinq outils de recherche et de visualisation permettant d’explorer de vastes corpus textuels. Ces outils sont plus spécifiquement conçus pour les sciences humaines et sociales. Pouvez-vous nous en parler brièvement et nous donner des nouvelles de leur développement depuis la dernière journée d’étude CO.SHS (voir le résumé ici)?
Selon ce que nous envisageons, les chercheur.e.s en sciences humaines et sociales pourront utiliser l’ensemble d’outils que nous avons mis au point en conjonction avec les barres de recherche comme celles qui existent déjà sur la plateforme Érudit. Pour notre premier outil, Textension, nous avons tenté d’offrir une visualisation en temps quasi réel aux chercheur.e.s qui possèdent peu de compétences techniques. Notre cadre traite une image fixe, p. ex. la photo d’une page de livre ou une image téléversée, et la transforme en visualisation interactive. Il suffit de prendre une photo avec son téléphone pour accéder au traitement des langues naturelles et à des visualisations interactives.
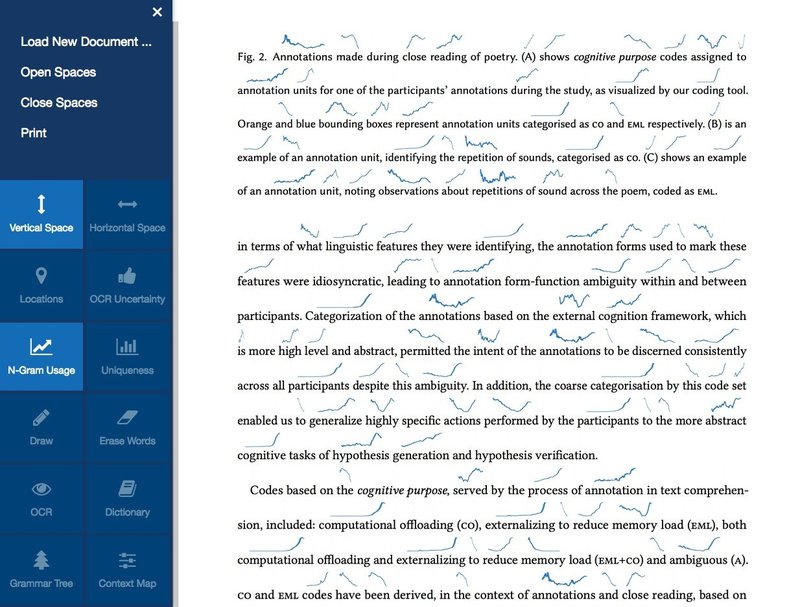
- Figure 1 : L’interface Textension avec des graphiques sparkline insérés automatiquement qui montrent l’historique des mots reconnus en anglais.
Notre deuxième outil est une plateforme de recherche améliorée qui permet aux utilisateur.trice.s d’effectuer des recherches dans le corpus d’Érudit d’une manière novatrice et emballante. Lors de nos entretiens avec les chercheur.e.s de CO.SHS, ils et elles ont tous parlé d’un problème similaire : comment interroger les corpus de documents. Nous avons conçu notre outil de recherche avec plusieurs éléments interactifs qui permettent aux utilisateur.trice.s de formuler des requêtes de différentes façons. Bien qu’une simple barre de recherche soit incluse (parce que c’est parfois tout ce qui est nécessaire), nous permettons également aux utilisateur.trice.s de téléverser des documents que nous modélisons pour ensuite leur retourner des documents semblables provenant de corpus plus vastes. Nous prenons également ces modèles et construisons une visualisation interactive qui permet une recherche fortuite à travers une hiérarchie visuelle de synonymes. En offrant plusieurs façons de formuler une requête, nous espérons faciliter la tâche aux chercheur.e.s qui interrogent des corpus.
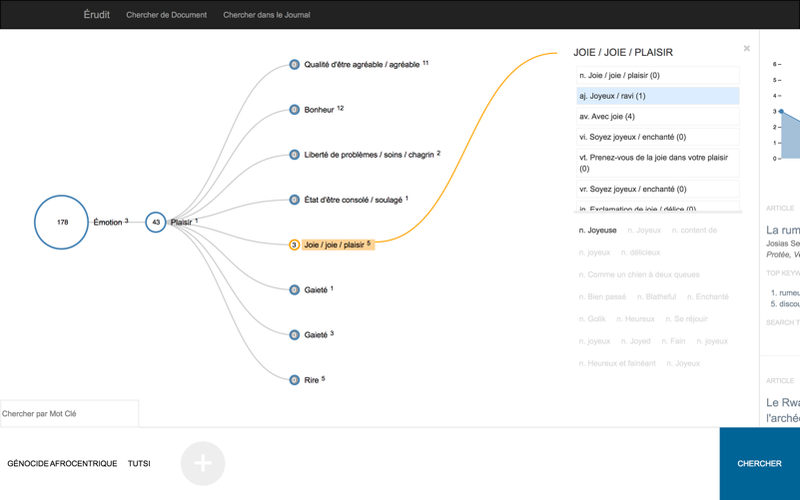
- Figure 2 : L’interface de recherche interactive. Ici, nous montrons la visualisation qui permet aux utilisateur.trice.s de trouver des termes de recherche apparentés à ceux contenus dans leur requête.
Le troisième projet a découlé d’une autre question soulevée lors de nos premiers entretiens avec les membres de CO.SHS. Leur question de recherche portait sur la façon dont le transfert de connaissances se fait au Québec et ailleurs. Nous avons commencé à nous pencher sur ce problème en créant une carte interactive en ligne qui montre les collaborations entre établissements de recherche et auteur.e.s d’articles du corpus d’Érudit. Les utilisateur.trice.s peuvent appliquer des filtres de recherche et faire un zoom avant et arrière pour essayer de trouver ce que nous appelons des « grappes de connaissances » par emplacement géographique.
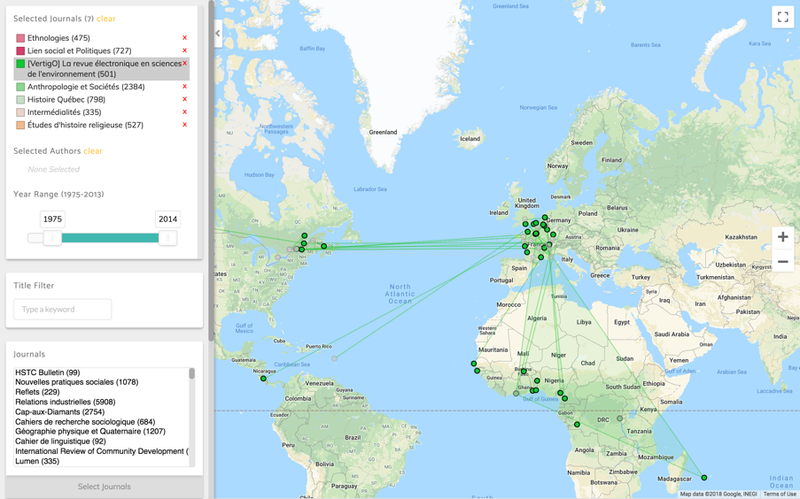
- Figure 3 : La carte interactive du « savoir »
Le quatrième projet vise à générer du trafic vers les revues en ligne. Grâce à nos techniques de modélisation de documents, les utilisateur.trice.s peuvent téléverser un document afin que nous l’appariions aux revues qui lui ressemblent le plus sur Érudit. Nous produisons ensuite une liste visuelle qui montre aux utilisateur.trice.s dans quelles revues leur document est le plus susceptible de s’insérer, dans l’ordre. Nous avons imaginé ce processus comme solution de rechange pour les chercheur.e.s qui avaient de la difficulté à interroger le corpus.
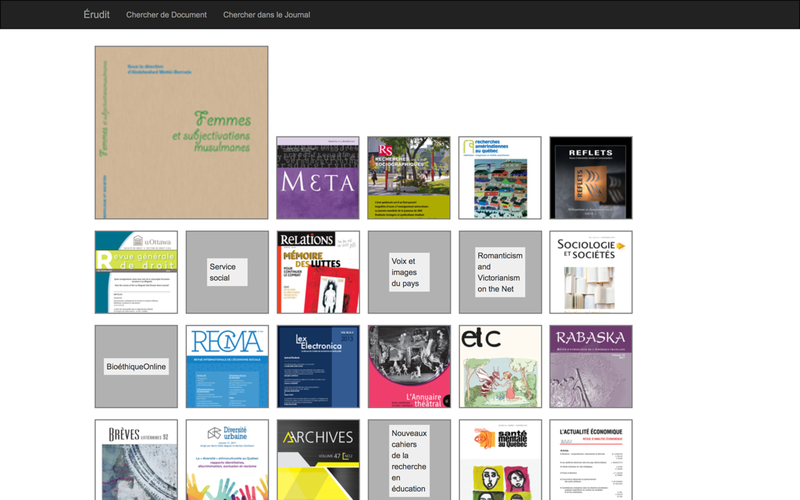
- Figure 4 : L’interface d’appariement des revues
Pleins feux sur l’analyse des contextes de citations
En ce moment, votre travail porte surtout sur un cinquième projet, Citation Galaxies, un outil d’analyse visuelle pour l’analyse des contextes des citations. Tout d’abord, pouvez-vous nous rappeler ce qu’est l’analyse des contextes de citations?
L’analyse des contextes de citations consiste à analyser les phrases entourant une citation dans un document savant. Les expert.e.s en bibliométrie utilisent ces phrases pour comprendre exactement comment, où et pourquoi les documents sont cités. Ce travail a des implications pour mieux comprendre, par exemple, comment les financements de recherche sont utilisés, ou encore pour évaluer la réussite de certains projets de recherche.
Quelle est la spécificité de cet outil? Quels seront les principaux cas d’utilisation?
En collaboration avec des expert.e.s en bibliométrie de l’Université de Montréal, nous avons construit une plateforme de visualisation interactive pour l’étude et le balisage des contextes de citations. Nous offrons à l’utilisateur.trice la possibilité de rechercher des séquences de mots et de définir quelle quantité de contexte entourant une citation il ou elle souhaite obtenir. Puis, nous produisons une visualisation à l’échelle du corpus qui lui permet d’identifier des ensembles de règles en fonction de ses propres critères de balisage. Actuellement, cet outil est utilisé pour l’analyse d’opinions, mais on peut l’adapter à d’autres usages. Le but de ce projet est d’avoir une boucle de rétroaction semi-automatisée qui utilise l’apprentissage machine pour suggérer d’autres règles pouvant aider les chercheur.e.s à baliser le corpus rapidement et précisément en fonction de leurs intérêts. Citation Galaxies a pour but d’améliorer les processus existants sans supprimer l’élément humain de l’équation.
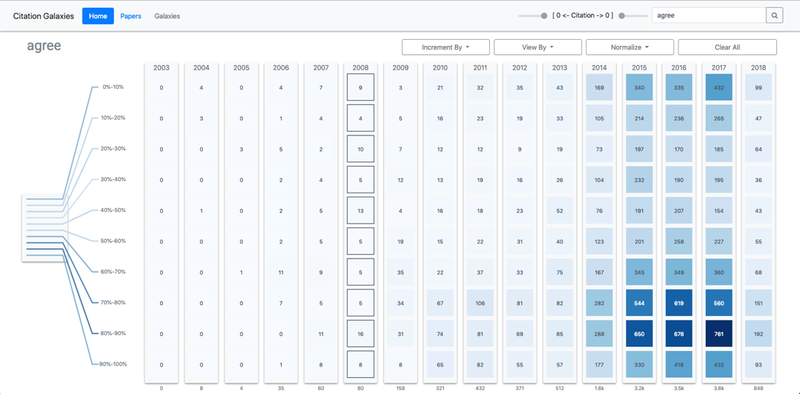
- Figure 5 : Un aperçu de la façon dont le terme de recherche spécifique agree est réparti sur l’ensemble d’un corpus
Vous semblez travailler en étroite collaboration avec le milieu de la recherche, notamment les expert.e.s en bibliométrie, afin d’aligner vos développements sur leurs besoins. Est-ce que c’est le cas?
Oui, ce projet est fondé sur le concept de conception itérative. Les expert.e.s en bibliométrie contribuent à ce processus. Tout d’abord, nous avons élaboré nos idées en nous inspirant des méthodes bibliométriques manuelles décrites dans leurs articles. Puis, nous avons peaufiné notre plan au fil de plusieurs réunions pour nous assurer que ce que nous produisons répondra aux exigences de leurs travaux et leur permettra de répondre à leurs questions de recherche.
Approche générale
Quel est l’objectif global ou la méthode qui sous-tend votre suite logicielle? Pouvez-vous nous en dire un peu plus sur ce qui rend votre approche unique et innovatrice?
L’objectif global de ces nouveaux outils est de trouver des moyens d’appuyer les flux de travail des chercheur.e.s en sciences humaines sans perturber leurs pratiques actuelles. Trop souvent, on construit des outils en prétendant qu’ils vont « révolutionner » le processus. Notre approche est différente. Nous voulions construire des outils qui s’intègrent parfaitement au travail déjà en cours. Nous avons entamé le processus de conception par des entrevues exhaustives avec les chercheur.e.s dont nous voulions soutenir le travail et nous avons essayé de concevoir tous nos outils en tenant compte de leurs besoins et de leurs travaux. Ce qui fait l’unicité de notre travail, c’est la nature conservatrice des interventions. Nous essayons d’éviter de dire aux utilisateur.trice.s ce qu’ils doivent faire de leur travail. Lorsqu’on part d’une conception qui vise d’abord et avant tout à soutenir les pratiques existantes, on se soumet en quelque sorte à ces dernières, ce qui aide à produire des outils véritablement pratiques.
À quelles difficultés avez-vous été confronté jusqu’à présent dans le développement de votre suite logicielle? Quel est le plan de travail pour les prochaines étapes?
Je (Adam) dis souvent à nos étudiant.e.s des cycles supérieurs que si je pouvais retourner en arrière et refaire mon doctorat, je travaillerais avec n’importes quelles données autres que le langage naturel! Bien que je dise cela à la blague, nos problèmes découlent presque toujours du fait qu’il est difficile de travailler avec le langage naturel en tant que données. Lorsqu’il s’agit d’organiser des ensembles de données, le langage naturel est toujours complexe, ambigu et indomptable. Pour chaque projet, l’étape de la préparation des données, qui consiste à organiser ces dernières afin qu’elles soient accessibles pour une machine, prend beaucoup de temps. Malheureusement, il n’y a aucun moyen d’éviter cette étape et chaque projet amène son lot de pièges.
En ce qui concerne les prochaines étapes, nous travaillons sur l’intégration en étroite collaboration avec l’équipe technique d’Érudit. Nos quatre premiers outils sont prêts à être déployés et nous essayons de trouver la meilleure façon d’y parvenir. Chaque projet donnera également lieu à une publication de recherche. Pour certains, nous en sommes à l’étape finale de la publication, tandis que pour d’autres, nous en sommes à préparer la soumission.